Another post, another screen shot. Almost looks like a real app :P
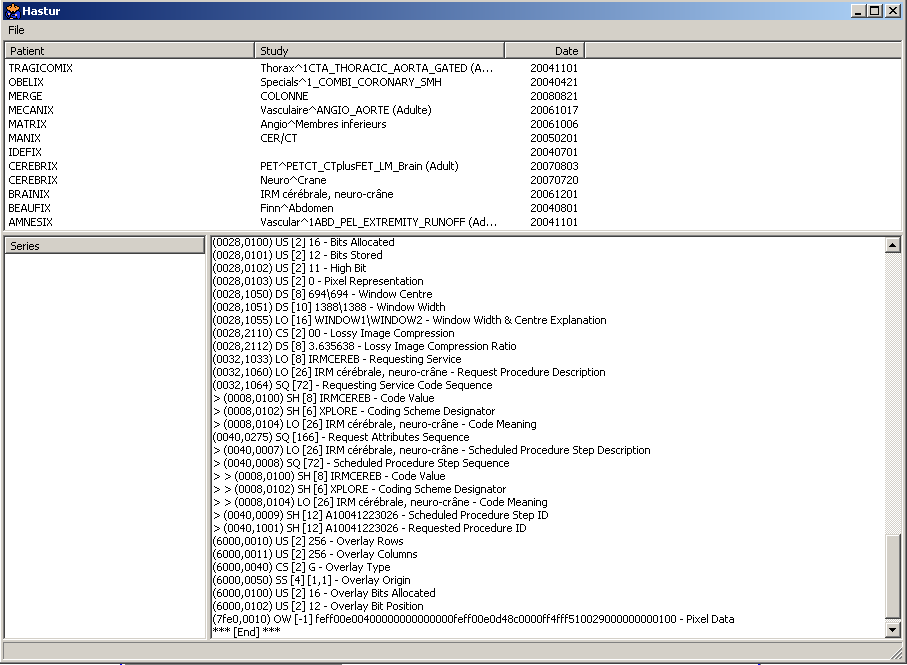
Differences are actually quite large though and quite a bit under the UI. An Sqlite3 database holds minimal patient, study and series info. Directories can be parsed for all their contents, recursively descending into sub-directories if desired. It's passably fast at parsing files and importing into the database too, at a bit over 1GB/min. That seems to be IO limited though as the CPU usage on my quad core peaks at about 10% much of which is system time. That will slow down as more data is inserted per file into the database so we'll have to see how bad it gets. Quietly pleased that it went through a lot of data without barfing once :)
The patient list does nothing but scroll and look pretty so far. The decoded file in the bottom right panel is one that was read independently of the database and patient list. There's no way to navigate to a file from the patient. Yet. Not least because individual files/images are not stored in the database yet...
I downloaded a whole bunch of the example files for Osirix only to discover they're mostly using the JPEG2000 transfer syntax. Arg. Vaguely fortunately, only the pixel data uses the actual JPEG2000 compression and the rest of the data is explicit VR little endian. Considerable staring at the standard and a hex editor, the addition of a new element decoding function (about 10 lines) and Hastur now reads all the metadata.
The pixel data itself is going to be a lot more trouble. It's actually held as an encapsulated document in the pixel data tag. The encapsulated document is a series of fragments encoded in a similar way to an SQ element. You can see the hex that delineates the individual fragments in the screen shot, the delimiter is "feff00e0". It won't be hard to write a parser to chew through the encapsulated document but since I don't have a JPEG2000 codec, that will wait.
Next up is storing files and images, linking bits of the UI together and figuring out the widget layout black art.
Thursday, 28 October 2010
{kind=link}
Friday, 8 October 2010
Tough Test Postponed...
...since it's far more important to have a custom icon on the main window of your UI :)
Much reading, an install of wxWidgets and wxHaskell, much more reading and many coffee later and Ihave something that might yet grow into something useful.
Since I both suck at naming and am quite fond of Cthulhu mythos, Hastur now exists. Terribly amusing pun on Hastur as he's the "One That Must Not Be Named". Hohoho. :P
Screenie here showing the first part of the aforementioned 40MB DICOM file.
BlackMage icon from Final Fantasy.
Much reading, an install of wxWidgets and wxHaskell, much more reading and many coffee later and Ihave something that might yet grow into something useful.
Since I both suck at naming and am quite fond of Cthulhu mythos, Hastur now exists. Terribly amusing pun on Hastur as he's the "One That Must Not Be Named". Hohoho. :P
Screenie here showing the first part of the aforementioned 40MB DICOM file.
{kind=link}
BlackMage icon from Final Fantasy.
Monday, 20 September 2010
Shambling Onward
The DICOM library has ballooned somewhat since last time :/ On the upside, the basic parser can now handle both of the simplest little-endian encoding schemes, all the 30+ possible value representations (VR - tag content type) and even nested sequences (both explicit and undefined lengths). I need to think about the exposed API and how to make it usable and also about how to get rid of the inelegant staircases of if-then-else in some methods. Ugly but it does actually work. This both surprised and pleased me the first time it ploughed, without error, through a 40MB multiframe file chock full of nested sequences and dumped it in readable form onto the console.
The library is now split out into modules with defined purposes (bytestream parsing, data dictionary, pretty printing and file reading) and only a very small amount of code has to live in IO. The rest of it is pure, albeit in fairly imperative form.
The implicit little-endian encoding is going to cause me a great deal more typing. Unlike the explicit LE encoding which supplies the VR in the tag itself, the implicit encoding expects you to just know what VR corresponds to each numerical tag. The only solution I know to that is to build a dictionary with the numerical tag as the key. This works as expected with the side-benefit that I can store the tag's textual description along with the VR for use when pretty printing. I do wonder how time consuming this will be to construct every time the library's used. There are a huge number of tags defined in DICOM of which I've used 300 and they took long enough to enter. Perhaps that is the price for trying to decode such a huge standard :/
A tough test to come is whether all this data can be successfully re-encoded into a bytestream then a file and read by an existing DICOM library. That will have to wait though, I need to see what I can do with the in-memory representation and that means it's time to build a UI app to look at pretty pictures in. wxHaskell here we come...
The library is now split out into modules with defined purposes (bytestream parsing, data dictionary, pretty printing and file reading) and only a very small amount of code has to live in IO. The rest of it is pure, albeit in fairly imperative form.
The implicit little-endian encoding is going to cause me a great deal more typing. Unlike the explicit LE encoding which supplies the VR in the tag itself, the implicit encoding expects you to just know what VR corresponds to each numerical tag. The only solution I know to that is to build a dictionary with the numerical tag as the key. This works as expected with the side-benefit that I can store the tag's textual description along with the VR for use when pretty printing. I do wonder how time consuming this will be to construct every time the library's used. There are a huge number of tags defined in DICOM of which I've used 300 and they took long enough to enter. Perhaps that is the price for trying to decode such a huge standard :/
A tough test to come is whether all this data can be successfully re-encoded into a bytestream then a file and read by an existing DICOM library. That will have to wait though, I need to see what I can do with the in-memory representation and that means it's time to build a UI app to look at pretty pictures in. wxHaskell here we come...
Thursday, 2 September 2010
Baby steps in Haskell
After lots of reading and sometimes comprehending over an embarrassingly long time, I now have a very limited but actually working piece of code in a functional language.
Usually, when trying to learn a new language, the hardest thing is deciding on a vaguely pointful thing to build as the learning experience. Not this time. I wanted to create a library for dealing with DICOM medical imaging data. The format's complex enough (lots of optional stuff, various encoding schemes, heirarchical object layout, etc) to be interesting and there are few really good parsers out there for it in procedural languages I'm used to.
There probably still won't be a good one for Haskell when I've finished but I'm hoping to have learned a lot. It's certainly been very hard going getting even this far but the following is a fragment of the output from my first efforts:
Doesn't look like much but it's decoded the group and element info (0002,0001) etc, the value representation (UI, CS, OB, etc) and correctly parsed the right number of bytes for the value. It's also split the file into the encapsulation (prelude, magic and metadata) and the actual DICOM object.
Ok, there's no error handling, it only knows one encoding scheme, doesn't grok heirarchical objects and there's no error handling but it's only 140 lines of code. A good third of that formats it nicely for printing on the console though so under 100 lines for a parser just blows me away. For what it does, that's probably excessively verbose but first it needs to work, then it can be refined and finally, if necessary, it can be made faster.
I don't think I've ever been so pleased with so little code before :o Haskell is very expressive but OMG has it been hard work learning to write even this little bit :/
Usually, when trying to learn a new language, the hardest thing is deciding on a vaguely pointful thing to build as the learning experience. Not this time. I wanted to create a library for dealing with DICOM medical imaging data. The format's complex enough (lots of optional stuff, various encoding schemes, heirarchical object layout, etc) to be interesting and there are few really good parsers out there for it in procedural languages I'm used to.
There probably still won't be a good one for Haskell when I've finished but I'm hoping to have learned a lot. It's certainly been very hard going getting even this far but the following is a fragment of the output from my first efforts:
Prelude: 0000000000000000000000000 ... 000
Magic: DICM
Metadata:
[ (0002,0000) UL [4] "\192\NUL\NUL\NUL"
, (0002,0001) OB [2] "\NUL\SOH"
, (0002,0002) UI [26] "1.2.840.10008.5.1.4.1.1.4\NUL"
, (0002,0003) UI [56] "1.3.12.2.1107.5.99.2.1951.30000009050612303648400002557\NUL"
, (0002,0010) UI [20] "1.2.840.10008.1.2.1\NUL"
, (0002,0012) UI [20] "1.3.12.2.1107.5.99.2"
, (0002,0013) SH [16] "XXXXXXX"
]
DICOM:
[ (0008,0005) CS [10] "ISO_IR 100"
, (0008,0008) CS [22] "ORIGINAL\\PRIMARY\\M\\ND "
, (0008,0012) DA [8] "2009XXXX"
, (0008,0013) TM [14] "140340.156000 "
, (0008,0016) UI [26] "1.2.840.10008.5.1.4.1.1.4\NUL"
.
.
.
]
Doesn't look like much but it's decoded the group and element info (0002,0001) etc, the value representation (UI, CS, OB, etc) and correctly parsed the right number of bytes for the value. It's also split the file into the encapsulation (prelude, magic and metadata) and the actual DICOM object.
Ok, there's no error handling, it only knows one encoding scheme, doesn't grok heirarchical objects and there's no error handling but it's only 140 lines of code. A good third of that formats it nicely for printing on the console though so under 100 lines for a parser just blows me away. For what it does, that's probably excessively verbose but first it needs to work, then it can be refined and finally, if necessary, it can be made faster.
I don't think I've ever been so pleased with so little code before :o Haskell is very expressive but OMG has it been hard work learning to write even this little bit :/
Wednesday, 7 July 2010
Truth Stinks
I wish I could claim this as my own:
"You can't polish a turd but glitter sticks to one extremely well"
I'm sure everyone can think of at least one unpolished turd in their lives, whether nationwide political or "that pillock at the office", which the glitter has stuck to but somehow doesn't disguise the awful smell...
Personally speaking, the quote reminded me of the last 13 years of Labour government and deluded worship of an invisible sky fairy, er, I mean, religion.
"You can't polish a turd but glitter sticks to one extremely well"
I'm sure everyone can think of at least one unpolished turd in their lives, whether nationwide political or "that pillock at the office", which the glitter has stuck to but somehow doesn't disguise the awful smell...
Personally speaking, the quote reminded me of the last 13 years of Labour government and deluded worship of an invisible sky fairy, er, I mean, religion.
Thursday, 17 June 2010
Trees the for wood the see can't
Make your own sentence from the title. I would do but apparently I can't see what's obvious... I love Subversion it gives me a quick way out of a horrific thinko. It's like a typo but involves a non-functional brain instead of non-functioning fingers. Revert is a fantastic action in a version control system. It's kinda like the Etch-a-Sketch end of the world where you decide it's all bad and you want to wipe the slate clean. Going back to how it was before I embarked on this idiotic mutually referencing tree bollocks for example...
What is now painfully obvious are a couple of things. I should never seek employment as the author of any form of garbage collection algorithm. A bit niche perhaps but it's good to know when you're backing a loser and get the hell out of Dodge. A more productive and practical observation is that if you want a tree to exist, all you need to do is ensure you hold a reference to the root node. This is the sort of idea that should get you a raised eyebrow and a courteous "get thee gone knave and procreate distantly" from any sane patent office on the grounds of being bloody obvious. Any country with such a patent office that doesn't allow idiocy like patenting either the bloody obvious or any form of software please apply by sending your address engraved in 18 point Arial on a gold brick of no less than 43.75 troy ounces. I can't guarantee anything beyond my admiration and proselytisation of your merits but 3lb of gold can't do any harm to my ambition to own an fun form of transport as I gather precious metals are having a bit of a renaissance as poly-chancellorous currencies fall into a cess pit. Best place really for political vanity in the face of economic reality.
Oh dear, bit of a tangent there. A true blue moon moment for my general mental track, honest. I was really just saying I'm a slow learner.
Happily that largely resolves the IDL difficulties of recent days. Self-inflicted wounds are always the most embarrassing to explain.
Joy! Rapture! I can now sleep! Oh, wait. No I can't cos that still leaves Haskell...
As an imperative programmer for 15+ years, the idea of code that not only doesn't maintain state but actively prevents you from doing so is difficult to the point of inducing significant cerebral meltage. OK, so I'm only on chapter 5 of "Too stupid to understand online tutorials? Read this, it takes it really slooooowly" but I can see the benefits of "pure" code versus "impure" code in Haskell.
"Pure" code in Haskell is code that has no state, is isolated from the outside world entirely and whose output depends entirely and solely on the inputs supplied. Thus "pure" code is mathematically provably correct. It is neither affected by the environment nor affects the environment itself. Therefore there can be no side-effects of executing it. Bugs in imperative code (C/C++/Java/C#/Fortran/Python/Ruby/Perl/many, many others...) can often be traced down, often at great expense in time, coffee and possibly headache medication, to unforeseen side-effects. Interestingly, to me at least, is the observation that the class methods I prefer are short, expressive ones which only depend on their input parameters... When I wrote them I thought they were intrinsically testable (depending solely on mockable inputs) and minimised problems. Prophetic? Hardly. Seems that good coding practices talk (regardless of language) and bullshit walks even if I pick them up almost by accident :/
"Impure" code in Haskell is code that deals with state, whether it is a loop counter (unnecessary with tail recursion or folds) or the existence of an uncertain and untrusted system (network, filesystem, DBMS, users...). You can do imperative stuff like I'm used to but it is rigidly separated from the pure code so side-effects can only happen where explicitly marked as possible.
At least this is my understanding so far. Does it show I'm trying to gauge my understanding of things by explaining them?
My slightly hazy impression that Haskell will support my most used imperative patterns like Observer, Strategy, Facade, Abstract Factory and Command? Jury's still out. Maybe the propaganda was true, functional programming does offer a completely different and better way to write code? It's certainly very expressive, I hope the serial loss of kip is worth it in the long run.
Maybe melting your brain is sometimes a good thing as it allows it to flow into new and better shapes?
What is now painfully obvious are a couple of things. I should never seek employment as the author of any form of garbage collection algorithm. A bit niche perhaps but it's good to know when you're backing a loser and get the hell out of Dodge. A more productive and practical observation is that if you want a tree to exist, all you need to do is ensure you hold a reference to the root node. This is the sort of idea that should get you a raised eyebrow and a courteous "get thee gone knave and procreate distantly" from any sane patent office on the grounds of being bloody obvious. Any country with such a patent office that doesn't allow idiocy like patenting either the bloody obvious or any form of software please apply by sending your address engraved in 18 point Arial on a gold brick of no less than 43.75 troy ounces. I can't guarantee anything beyond my admiration and proselytisation of your merits but 3lb of gold can't do any harm to my ambition to own an fun form of transport as I gather precious metals are having a bit of a renaissance as poly-chancellorous currencies fall into a cess pit. Best place really for political vanity in the face of economic reality.
Oh dear, bit of a tangent there. A true blue moon moment for my general mental track, honest. I was really just saying I'm a slow learner.
Happily that largely resolves the IDL difficulties of recent days. Self-inflicted wounds are always the most embarrassing to explain.
Joy! Rapture! I can now sleep! Oh, wait. No I can't cos that still leaves Haskell...
As an imperative programmer for 15+ years, the idea of code that not only doesn't maintain state but actively prevents you from doing so is difficult to the point of inducing significant cerebral meltage. OK, so I'm only on chapter 5 of "Too stupid to understand online tutorials? Read this, it takes it really slooooowly" but I can see the benefits of "pure" code versus "impure" code in Haskell.
"Pure" code in Haskell is code that has no state, is isolated from the outside world entirely and whose output depends entirely and solely on the inputs supplied. Thus "pure" code is mathematically provably correct. It is neither affected by the environment nor affects the environment itself. Therefore there can be no side-effects of executing it. Bugs in imperative code (C/C++/Java/C#/Fortran/Python/Ruby/Perl/many, many others...) can often be traced down, often at great expense in time, coffee and possibly headache medication, to unforeseen side-effects. Interestingly, to me at least, is the observation that the class methods I prefer are short, expressive ones which only depend on their input parameters... When I wrote them I thought they were intrinsically testable (depending solely on mockable inputs) and minimised problems. Prophetic? Hardly. Seems that good coding practices talk (regardless of language) and bullshit walks even if I pick them up almost by accident :/
"Impure" code in Haskell is code that deals with state, whether it is a loop counter (unnecessary with tail recursion or folds) or the existence of an uncertain and untrusted system (network, filesystem, DBMS, users...). You can do imperative stuff like I'm used to but it is rigidly separated from the pure code so side-effects can only happen where explicitly marked as possible.
At least this is my understanding so far. Does it show I'm trying to gauge my understanding of things by explaining them?
My slightly hazy impression that Haskell will support my most used imperative patterns like Observer, Strategy, Facade, Abstract Factory and Command? Jury's still out. Maybe the propaganda was true, functional programming does offer a completely different and better way to write code? It's certainly very expressive, I hope the serial loss of kip is worth it in the long run.
Maybe melting your brain is sometimes a good thing as it allows it to flow into new and better shapes?
Tuesday, 15 June 2010
Sleep
I've had it explained, with diagrams and everything, but my dear brain has no truck with the concept. Thus it is that I'm wide awake at 0300 with programming problems vying for mindspace. Technically, one programming problem and one programming language.
The problem is one of memory management. My employer's language of choice, IDL, is great if what you want to do is prototype some procedural code with the backing of some convenient built-in libraries for DICOM, XML and lots of maths gubbins. It's (fairly) cross platform too which is nice in a mixed Windows/OS X/Linux environment. Pity I'm developing applications that have to behave like proper applications. You know the ones: functionally complete and correct, easy to use, robust (in the face of some of the users' idiosyncracies), pretty and as short a bug list as possible.
So happens that IDL supports objects as well as procedural code. Hurrah! Because of this, I can bring lots of OOP goodness to bear on my applications! On second thoughts, perhaps that should read: "Despite this, I can..." IDL is weakly and dynamically typed which means the "compiler" is little more than a glorified syntax checker and everything fails at runtime. Lots of folks like that sort of language, I'm just not one of them, especially when it comes to anything more than trivial applications. IDL also has no concept of private, protected or public access modifiers for classes. No C/C++'s #define nor Java's public static final class members for constants. No standard library for fundamental data structures like lists, maps, red-black trees. I've written the libraries or worked around most other "features" but there's one that's recently risen up to bite me. Again.
No garbage collector.
There is, sort of. As long as you aren't using objects. I use objects as a matter of course because it's the only way to get a measure of type safety in IDL. So that left me with implementing reference counting. It's worked extremely well for the last five years or so, everything deriving from a single base class implementing addRef() and destroy() to change the ref count and which finally calls its own destructor when the ref count hits zero.
There were a few wrinkles with things like ensuring correct destruction of objects that were both observed and observer in the Observer pattern but nothing serious. As long as I avoided one construct, that is: a tree where, as well as the parent holding references to its children, the children each hold references to the parent. This mutual holding of references ensures that, without special handling, at no time can the reference count of parent or child reach zero and so the tree can never be destroyed.
This is the nub of the problem, I cannot see how to avoid needing this construct. I need to be able to hold a reference to one node and navigate the whole tree, ancestors and children, from that one node. I have to find a way to both ensure that the tree is destroyed when no longer needed, but not until exactly none of the nodes of the tree are referenced by any object outside the tree itself. The only solution I've come up with so far is to do a brute force search of the tree for a node who has a ref count that exceeds (parent + number of children). Obviously this has worst-case performance of O(n) where n is the number of nodes in the tree. Inelegant and inefficient :( Sadly, it's the only solution my nocturnal brain can come up with. Hopefully tomorrow I'll get it implemented correctly so at least I'll actually have a working solution. If the real world performance is unacceptable then I foresee painful optimisation.
The other thing fighting for thinking power is Haskell. I've never used functional programming before but I read that it is to object-oriented design what object-oriented design is to structured procedural coding. Clearly the thing to do is learn it and find out... You've got to wonder about a language where you can write a quicksort in one or two lines of code and a power of 2 FFT and inverseFFT in less than 50 lines including comments, right? Cue lots of time awake while I try to assimilate lots of new and alien concepts :/ How functional programming and my comfortable world of imperative Java/IDL relate in another post.
The problem is one of memory management. My employer's language of choice, IDL, is great if what you want to do is prototype some procedural code with the backing of some convenient built-in libraries for DICOM, XML and lots of maths gubbins. It's (fairly) cross platform too which is nice in a mixed Windows/OS X/Linux environment. Pity I'm developing applications that have to behave like proper applications. You know the ones: functionally complete and correct, easy to use, robust (in the face of some of the users' idiosyncracies), pretty and as short a bug list as possible.
So happens that IDL supports objects as well as procedural code. Hurrah! Because of this, I can bring lots of OOP goodness to bear on my applications! On second thoughts, perhaps that should read: "Despite this, I can..." IDL is weakly and dynamically typed which means the "compiler" is little more than a glorified syntax checker and everything fails at runtime. Lots of folks like that sort of language, I'm just not one of them, especially when it comes to anything more than trivial applications. IDL also has no concept of private, protected or public access modifiers for classes. No C/C++'s #define nor Java's public static final class members for constants. No standard library for fundamental data structures like lists, maps, red-black trees. I've written the libraries or worked around most other "features" but there's one that's recently risen up to bite me. Again.
No garbage collector.
There is, sort of. As long as you aren't using objects. I use objects as a matter of course because it's the only way to get a measure of type safety in IDL. So that left me with implementing reference counting. It's worked extremely well for the last five years or so, everything deriving from a single base class implementing addRef() and destroy() to change the ref count and which finally calls its own destructor when the ref count hits zero.
There were a few wrinkles with things like ensuring correct destruction of objects that were both observed and observer in the Observer pattern but nothing serious. As long as I avoided one construct, that is: a tree where, as well as the parent holding references to its children, the children each hold references to the parent. This mutual holding of references ensures that, without special handling, at no time can the reference count of parent or child reach zero and so the tree can never be destroyed.
This is the nub of the problem, I cannot see how to avoid needing this construct. I need to be able to hold a reference to one node and navigate the whole tree, ancestors and children, from that one node. I have to find a way to both ensure that the tree is destroyed when no longer needed, but not until exactly none of the nodes of the tree are referenced by any object outside the tree itself. The only solution I've come up with so far is to do a brute force search of the tree for a node who has a ref count that exceeds (parent + number of children). Obviously this has worst-case performance of O(n) where n is the number of nodes in the tree. Inelegant and inefficient :( Sadly, it's the only solution my nocturnal brain can come up with. Hopefully tomorrow I'll get it implemented correctly so at least I'll actually have a working solution. If the real world performance is unacceptable then I foresee painful optimisation.
The other thing fighting for thinking power is Haskell. I've never used functional programming before but I read that it is to object-oriented design what object-oriented design is to structured procedural coding. Clearly the thing to do is learn it and find out... You've got to wonder about a language where you can write a quicksort in one or two lines of code and a power of 2 FFT and inverseFFT in less than 50 lines including comments, right? Cue lots of time awake while I try to assimilate lots of new and alien concepts :/ How functional programming and my comfortable world of imperative Java/IDL relate in another post.
Subscribe to:
Posts (Atom)